機械学習の基礎を学ぶための「機械学習入門」。以下のページを参考にして、日本語解説を加えました。ソースコードも以下にあります。
今回は、Excelのような数値データ(テーブルデータ)を処理するために最も用いられるpandasというモジュールについて説明します。
Pandasを使用してデータを理解する
機械学習プロジェクトの最初のステップは、データに精通することです。 そのためにPandasライブラリを使用します。
Pandasは、データサイエンティストがデータの探索と操作に使用する主要なツールです。 ほとんどの人は、コードのなかでpandasをpdと省略しています。
import pandas as pdPandasライブラリの最も重要な部分はDataFrameです。 DataFrameは、Excelのシート、またはSQLデータベースのテーブルに似たテーブルデータのタイプを保持します。
例として、オーストラリアのメルボルンの住宅価格に関するデータを見てみましょう。 。
サンプルデータは、ファイルパス../input/melbourne-housing-snapshot/melb_data.csvにあるとします。
次のコマンドを使用して、データをロードして調査します。
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
melbourne_data.describe()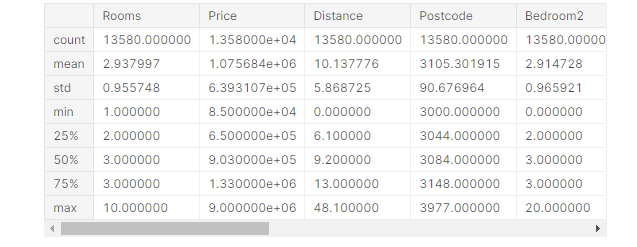
データの説明の解釈
.describe()の出力には、データセットの各列に対して、以下の8つの数値が表示されます。
count:行の数(欠損していない行)
mean:平均値
std:標準偏差 (値がどの程度数値的に分散しているか)
min、25%、50%、75%、max:
リストの値を小さいほうから4分の1進んだ数値が25%の値です(「25パーセンタイル」と発音します)。 50パーセンタイルと75パーセンタイルも同様に定義されます。
meansは、欠損していない行と説明しています。欠測値は多くの理由で発生します。 たとえば、寝室が1つしかない家の場合、2つ目の寝室のサイズは欠損値となります。欠損値については、後ほど学びます。
今回はPandasの基礎について学びました。次は簡単な機械学習モデルを構築してみます。
コメント