まず、機械学習モデルの仕組みと使用方法から始めます。以前に統計モデリングや機械学習を行ったことがある場合、この記事は基本的なことだと感じるかもしれませんが、じきに強力なモデルの構築に進みます。
住宅価格の予測
住宅価格についての予測モデルを考えます。
不動産屋は、過去の家の価格から、新しい物件の価格を予測しています。
機械学習も同じように機能します。過去のデータから、新しいデータを予測するのです。
今回は、決定木と呼ばれるモデルから始めます。決定木は理解しやすく、データサイエンスのモデルの基本となります。単純な決定木から始めます。
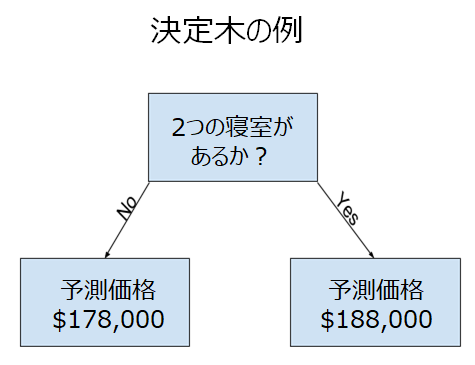
家を2つのカテゴリーだけに分ける決定木です。
データを使用して、家を2つのグループに分割する方法を決定し、次に各グループの予測価格を決定します。 データからパターンを見つける作業は、モデルのフィッティングまたはトレーニングと呼ばれます。 モデルの適合に使用されるデータは、トレーニングデータと呼ばれます。モデルが適合したら、それを新しいデータに適用して、追加の住宅の価格を予測できます。
決定木の改善
次の2つの決定木のうち、どちらの方が妥当な決定木に思えるでしょうか。
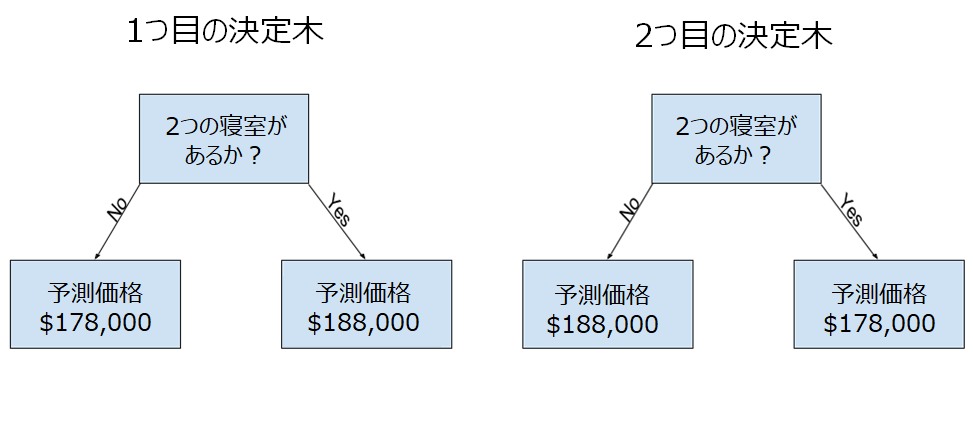
左側の決定木は、寝室の多い家は、寝室の少ない家よりも高い価格で販売される傾向があるという現実を捉えているため、より理にかなっています。 このモデルの欠点は、バスルームの数、ロットサイズ、場所など、住宅価格に影響を与える要因の多くを考慮できないことです。
より多くの「分岐」を持つツリーを使用して、より多くの要素を考慮できます。 これらは「より深い」木と呼ばれます。 各家の区画の合計サイズも考慮した決定木は、次のようになります。
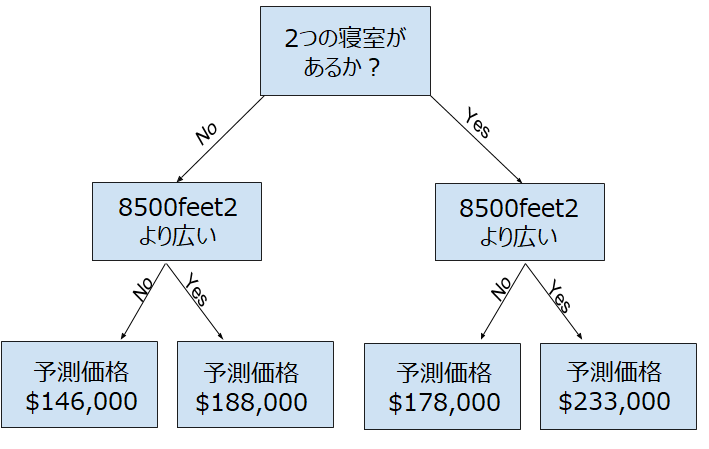
決定木を用いて、その家の特性に対応するパスを選択することで、家の価格を予測できます。
コメント