
Open AIが画像生成のDALL-E3を発表しました。ChatGTPの課金版と、Bingブラウザで利用できるとのことで、休日の暇な時間を使って遊び倒してみました。
簡単なプロンプトを入力するだけで、意図したようなイラストや写真がガンガン生成できたので、画像とプロンプトと一緒に紹介します。
[ad]
Open AiがDALL-E3を発表

OpenAIは最新のテキストから画像へのジェネレーターであるDALL-E 3を発表し、その優れた新機能をいくつか紹介しました。
DALL-E 3は、ユーザーがプロンプトテキストに書いた「空間的関係」をよりよく理解し、ユーザーが説明した場所に図や物体を配置する画像を生成する能力を持っています。これはプロンプトを正確にレンダリングできることを意味し、画像生成の新たなレベルへの飛躍的な進化が期待できます。
DALL-E 3は、OpenAIの大規模言語モデル(LLM)の月額20ドルの有料サブスクリプション層であるChatGPT Plusと、企業向けChatGPT for Enterpriseプランに導入されています。
筆者もChatGPT Plusに登録していますので、DALL-E 3で遊び倒してみました。
どんな種類の画像を生成できる?
どのような画像を生成できるのか試すために、写真、イラスト、マンガ、テキスト、図解、地図、3DCGをテーマにしてそれぞれ画像を生成してもらいました。
写真
まずは、簡単な写真を生成できるのか試してみます。
日本の写真を書いて




プロンプトを与えると、DALL-E3は4枚の画像を出力してくれます。「写真」を指示しましたが、写真と言うより「イラストと写真の中間」のような印象です。
イラスト
では、イラストを描いて、と指定するとどのような画像が生成されるのでしょうか。
日本のイラストを描いて




イラストチックな画像が生成されました。イラストには強いのかもしれません。
マンガ
漫画は生成できるのでしょうか。
日本の漫画を描いて




「イラスト」と「マンガ」には、大きな違いは見られませんでした。4コマ漫画のようなものを想像していたので、少し残念です。
そこで、もう少し詳細にプロンプトを与えてみることにしました。
以下のような流れの、4コマ漫画を描いて。
1:パンを加えた少女が走っている
2:少女が交差点で少年とぶつかる
3:少年は怪訝な表情で少女をにらめつけて去っていく
4:学校につくと、その少年が転校生としてクラスで紹介されていた

プロンプトを詳細に与えると、しっかりとした4コマ漫画が生成されました(1枚の画像として生成されます)。特に白黒を指示していないのに、ちゃんと白黒画像で出力してくれますし、登場人物の容姿にも一貫性があります。
一方で、意図しない状況のコマも見受けられます。
- パンを加えた少女が走っていない
- 少年とぶつかってもいないし、少年は怪訝な表情をしていない
- 学校についてもいない
- 転校生であることは描写されていない
プロンプトにもっと工夫を加えて、詳細な描写を加えれば、より正確に表現してくれるのかもしれません。
[ad]
テキスト・図解
日本語文字の入った画像を生成できるのか試してみました。
日本を表現するテキストの画像を生成して




日本語で意味のある文章は生成されませんでした。4枚目の画像は、画像中に文字らしきものは見えますが、文章の意味を成していません。日本語テキスト入りの画像を生成することは難しいようです。
一方で、英語プロンプトでLSI(Large Scale Integration)とディスクリート半導体を説明する画像を生成させると、意味のある英語での説明がなされた画像が生成されました。
日本語の文字入りの画像生成は難しいですが、英語であれば「それっぽい」図解画像をつくることはできるようです。
地図
地図はどうでしょうか。日本地図を描いてもらいます。
日本の地図を描いて
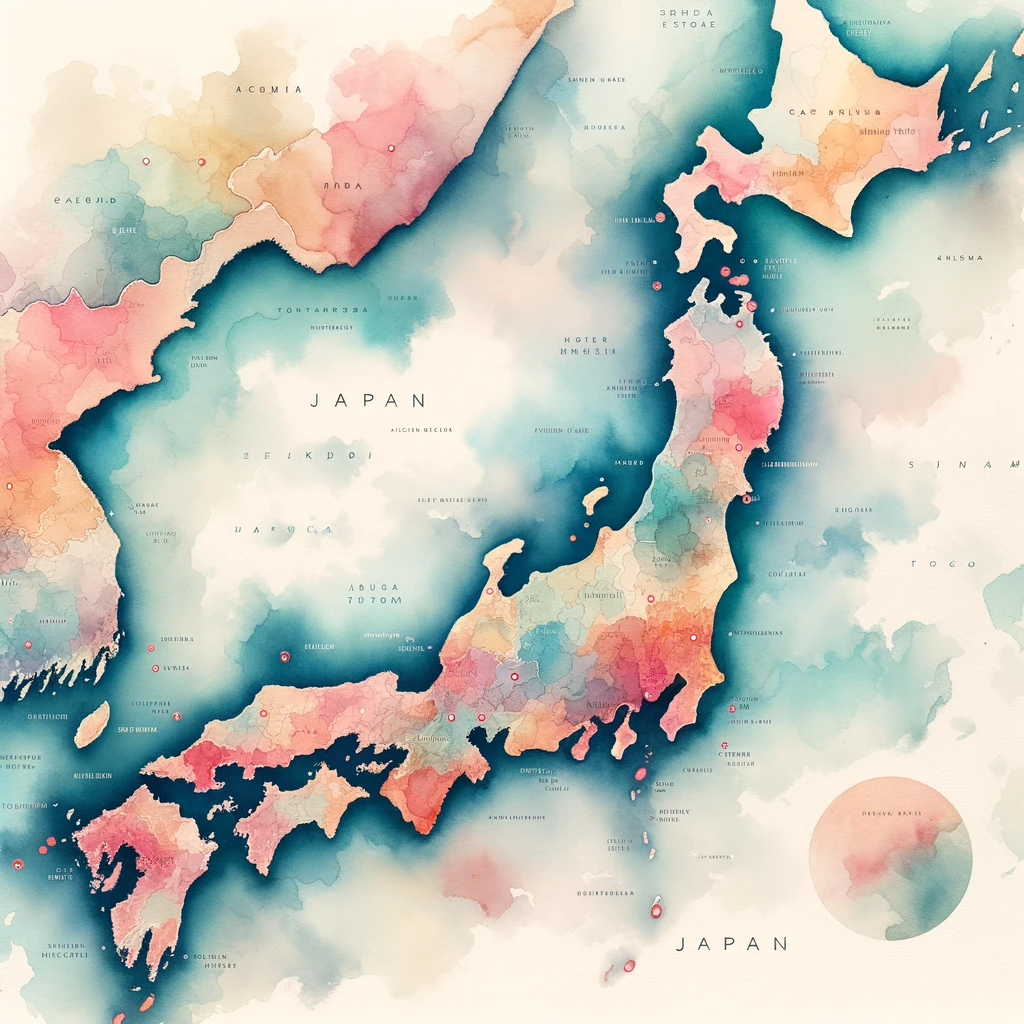
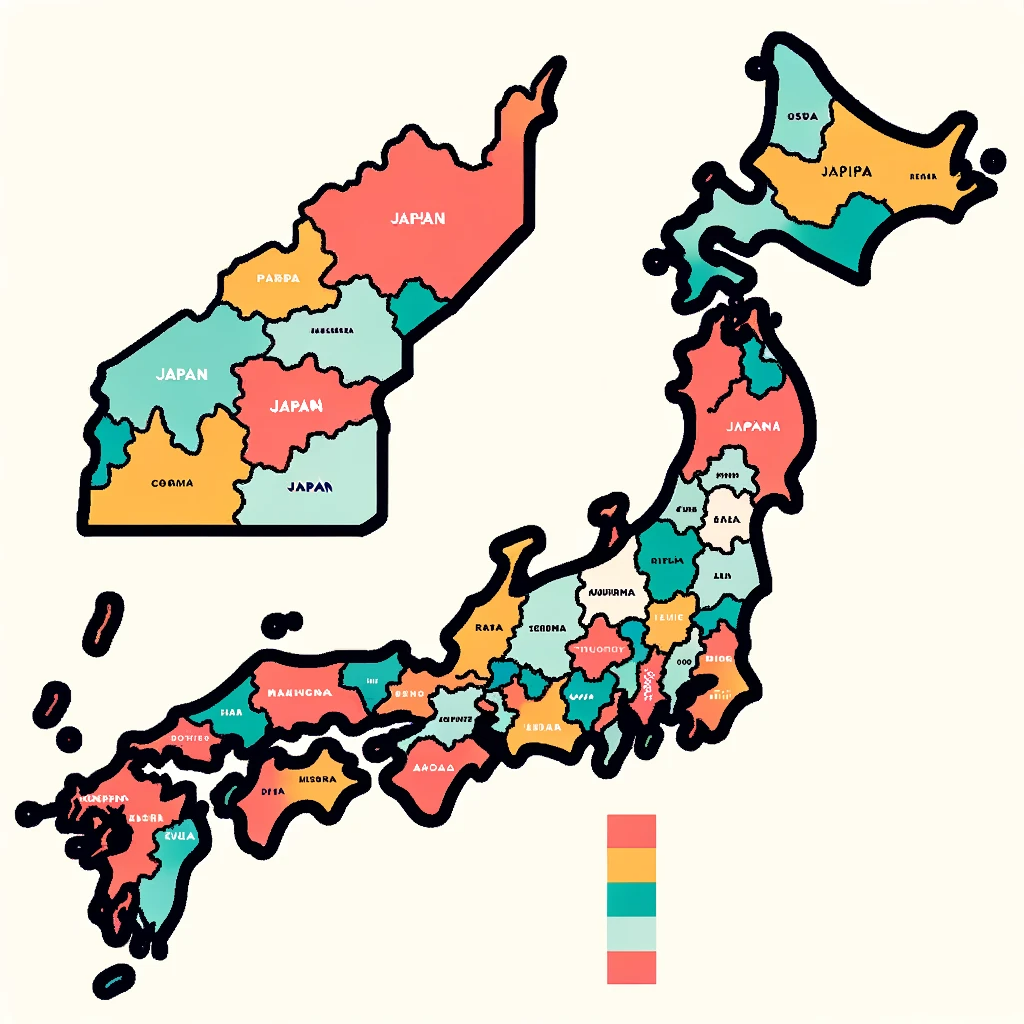
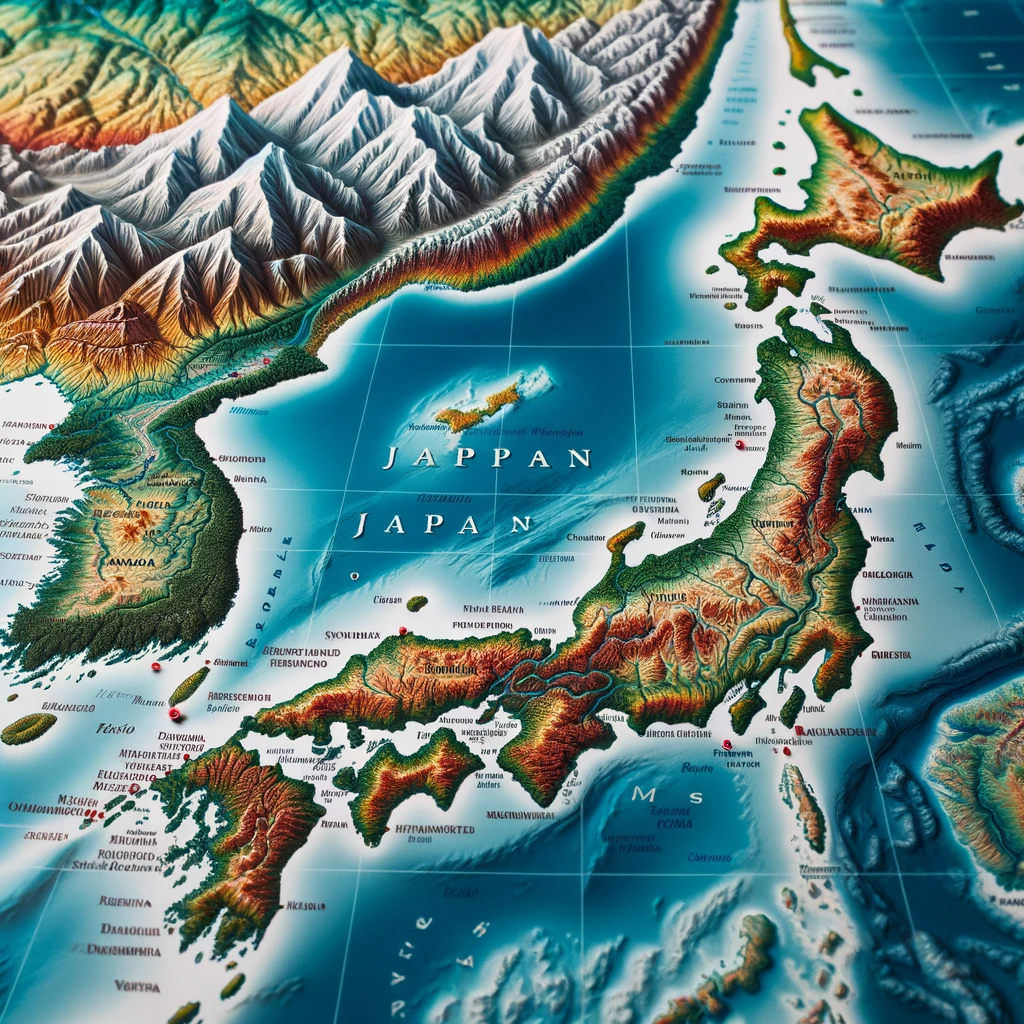
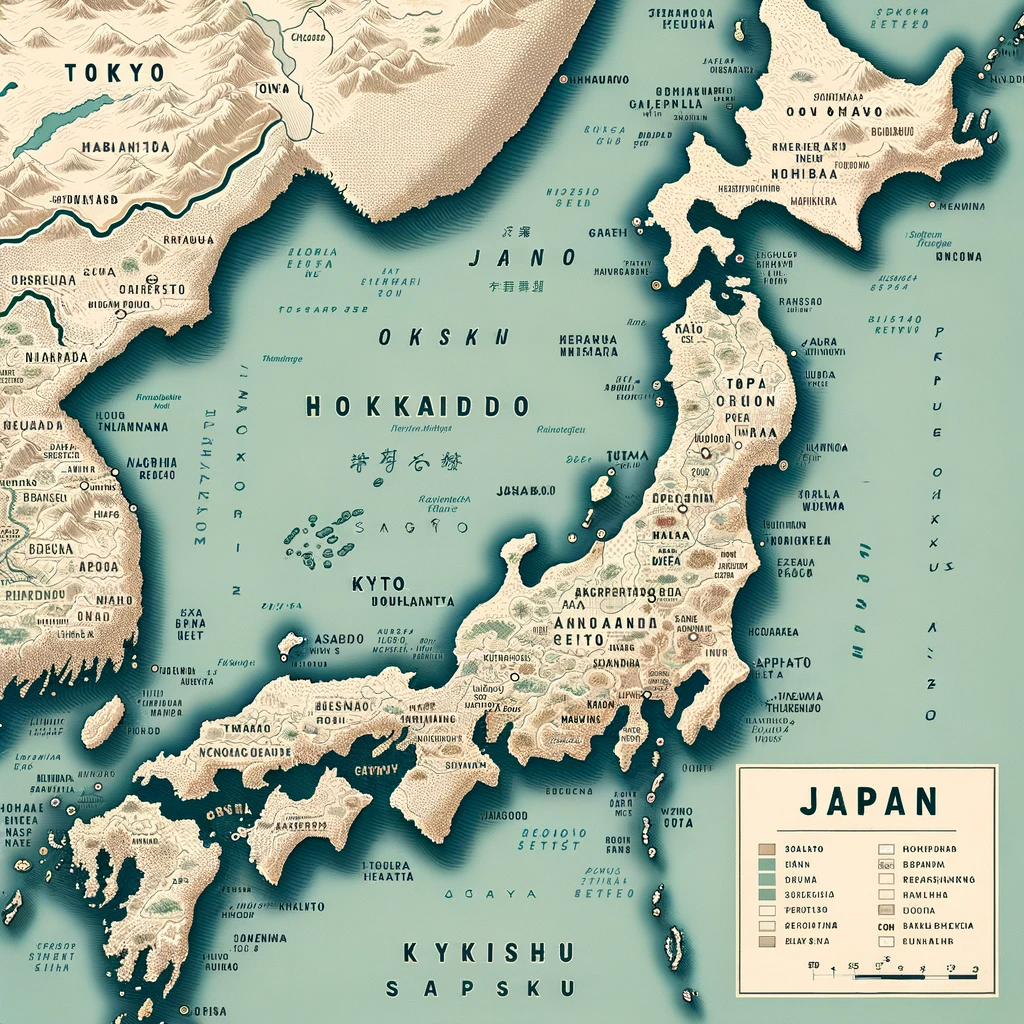
日本列島は「それっぽい」形をしてます。2枚目は都道府県まで描いていますね。都道府県の細部は適当(東京がない、北海道が分裂、和歌山が異常にデカいなど)ですが、「それっぽい」画像を生成するには十分なようです。
経路図まで表現できるのであれば素晴らしいと思い、以下のようなプロンプトを試してみました。
東京から大阪までの新幹線のルートを地図で描いて
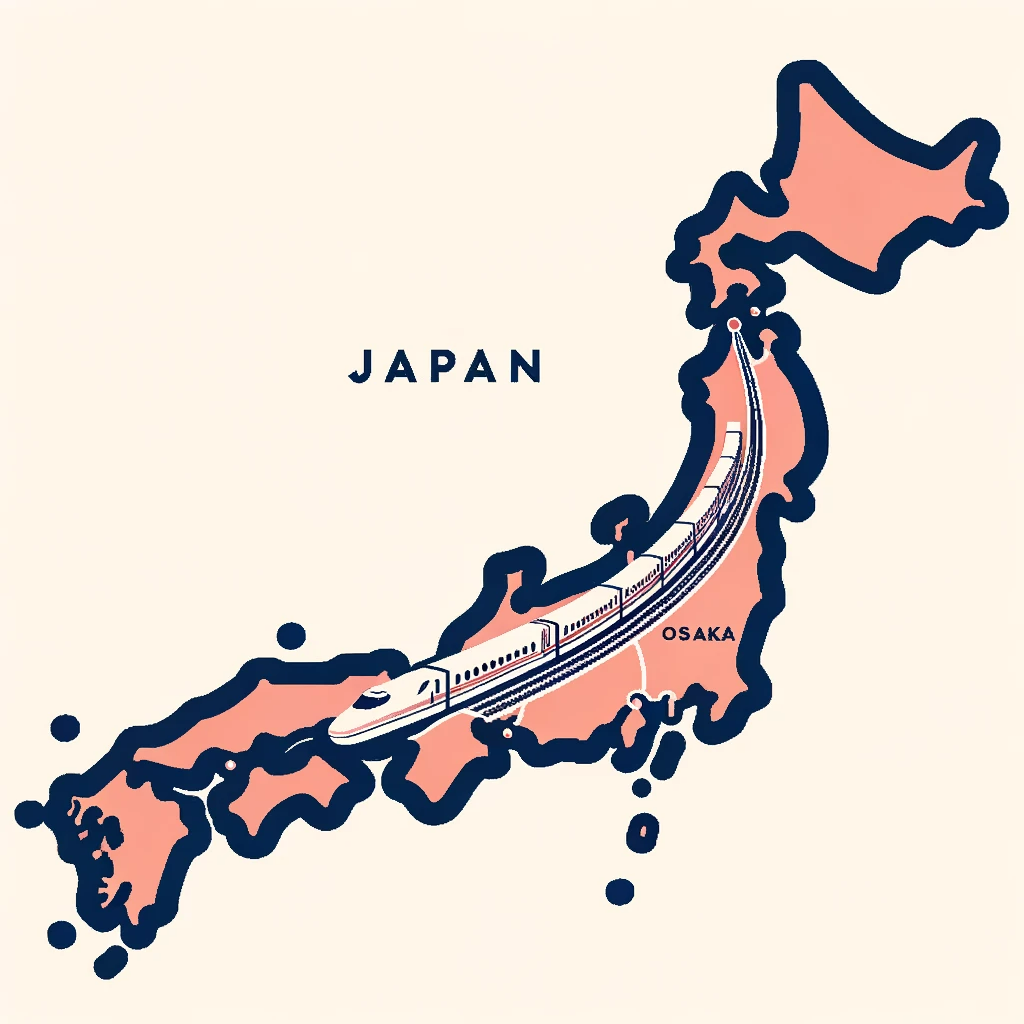

東京-大阪間が東海道を通る意識はあるようですが、東京と大阪の位置を認識できていないようで、説明に使えるような地図は得られませんでした。画像が意味を成すようにするには、もう少し詳しくプロンプトを書いてやる必要があるみたいですね。
3D-CG
3D-CGは生成できるのでしょうか。
日本を表現する3DのCGを描いて




コンピュータグラフィックスのようなものを出力してくれました。期待していたほど3DCGっぽい画像ではなく、イラストと融合された雰囲気です。
[ad]
イラストのデザインをどこまで制御できるか
イラストを、どこまで自分の意図したように生成できるかも試してみました。イラストも、その描画方法や色の組み合わせ、描画されるモノまで詳細に再現できるのでしょうか。
アイソメトリックイラストを描いてもらう
日本をテーマにしたアイソメトリックイラストを描いて




「アイソメトリックイラスト」(等角投影法で描いたイラスト)という指定をして生成してもらいました。ちゃんと指示通りのイラストになっています。
フラットデザインにしてみる
日本をテーマにしたアイソメトリックイラスト
フラットデザインで描いて




フラットかつアイソメトリックの画像も生成されています。流行りのイラストのタイプがわかっていれば、どのようなイラストにしたいのかを指示するだけで、今風の画像が生成できそうです。
東京タワーを置いてみる
せっかくなので、東京を意識して「東京タワー」を画像に含めるようにしてもらいます。
日本をテーマにしたアイソメトリックイラスト
フラットデザインで描いて
中心に東京タワーを描いて。




ちゃんと東京タワーが中心に設置されたイラストが生成されました。東京タワーの形状もとてもリアルです。プロンプトが複雑になるほど、生成される4枚の画像のバラツキも少なくなっています。
山手線と羽田空港も
東京なので、山手線と羽田空港を描いてもらいます。
日本をテーマにしたアイソメトリックイラスト、
フラットデザインで描いて
中心に東京タワーを描いて。
周囲をJR山手線が回るようにして
羽田空港も描いて



先ほどよりも「島っぽさ」が協調されています。飛行機や電車、車も配置されていて、プロンプト通りの画像が生成されています。
ここまで詳細に指定すると、生成される画像も「同じようなもの」が多くなってきます。東京を表現するイラストにはこれで十分ですね。
[ad]
自分のサイトで使えそうな画像を生成する
せっかくなので、このサイトで使えそうな素材をいくつか作ってみたいと思います。
IT系のWEBに使えそうな素材
IT系のwebで使えそうなアイソメトリックイラストを描いて。 色は青と紫、白黒グレーを基調にして



良い感じです。量子コンピュータやクラウドの記事のサムネ画像に使えそうです。
工学シミュレーションの素材
当サイトは、CADやCAEソフトを使った工学系の3Dシミュレーションも扱っているので、そのへんの記事に使えそうな素材を作ってみてもらいます。
パソコンで3D-CADを操作している様子をアイソメトリックイラストを描いて。 色は青と紫、白黒グレーを基調にして、黄色をアクセントとして加えて



これだけ簡単なプロンプトで、意図したとおりの結果が得られています。
黄色をアクセントに、という指示も通っています。かなり優秀ですね。
当然、よく見ると「なんだこれは?」というツッコミどころもありますが、記事のサムネイルを作るぶんには全く問題ないですね。
EV用電池の画像
EVに搭載する電池のテーマも多く扱っているので、その素材を作ってもらいます。
自動車に搭載された電池をアイソメトリックイラストを描いて。 色は青と紫、白黒グレーを基調にして、黄色をアクセントとして加えて



とても良い感じです。特に2枚目のが像は、床下にバッテリーパックを搭載しているようにも見えます。
イラストレーター、本当に仕事が減りそう…
ブログ記事の文字をそのままプロンプトにする
「OpenAIのAPIを活用したらGPT-4の料金が思ったより高かった件」という記事の「ChatGPTのAPIを本で勉強して使ってみました」という趣旨の文章を、そのままプロンプトにしてみました。この文章を表現する画像は生成されるのでしょうか。
以下の文章を連想させるアイソメトリックイラストを描いて。色は青と紫、白黒グレーを基調にして、黄色をアクセントとして加えて。
APIを使って、操作を自動化する方法も考えていましたが、なかなか難しくて試していませんでした。先日、「Python / JavaScriptによるOpen AIプログラミング」という本を見つけて、自分でもやってみようと思い購入。経験を積むためにもとりあえず10ドルほど課金して、試してみることにしました。
ChatGPTの使い方をマスターすると、作業を自動化することができて、とても便利です。例えば、ブログを書く時にミスをチェックしたり、定型的な作業を自動化することができます。毎回同じ作業をする手間を省くことができます。



生成された画像です。期待通りです。ChatGPTのAPIを本で学んで使っている様子が描かれています。
1枚目の画像などは、画像中にChatGPTの文字が入っていますし、2枚目の画像にはPythonのロゴも含まれています。英語で意味のある単語が書かれており、そのまま画像として使えそうです。
ブログの文章をそのままプロンプトにして、ブログ用の画像を生成する時代が訪れています。
生成した画像を出発点に改良して貰う
DALL-E 3はチャットと融合した画像生成サービスなので、生成した画像と共に、「フィードバックをお聞かせいただければさらに調整をします」といった返事をしてきます。
新しいアイソメトリックイラストを生成しました。どれがお好みでしょうか?フィードバックをお聞かせいただければ、さらに調整や変更を行います。




フィードバックをお聞かせいただければ調整する、とのことなので、以下のように修正してもらいます。
1枚目の画像が好みです。ChatGPTという文字が入っているのが特に良いです。 この画像をもとに、Pythonのアイコンと、Pythonという文字を加えてもらえますか?


指示した通り、pythonという文字と、pythonのアイコンが追加されています。(2枚目右下)
このように、意図した画像が生成されたら、その画像の細部は「もっとこうして!」と注文して、修正していくことが可能なようです。
生成される画像サイズは?

DALL-E 3で生成された画像はダウンロードが可能です。そのファイルサイズと解像度は以下の通りです。
- 1~2 MB
- 1024×1024ピクセル
そこそこ高解像な画像が生成されることが分かります。縦横の比率は1:1のスクエア。画像サイズは、その内容寄りますが1~2MBであるものがほとんどです。

2024年1月末時点で、DALL-Eで生成する画像の縦横比を変えることができるようになりました。デフォルトでは正方形(1024×1024ピクセル)の画像が生成されますが、ワイド画像(1792×1024ピクセル)や縦長のポートレート形式(1024×1792ピクセル)など、異なる縦横比での画像生成も可能です。
生成する画像サイズは調整できるのか?
画像サイズを制御できないか、以下のようなプロンプトで試してみました。
全固体電池の図解画像を生成して。
生成する画像は、500*500ピクセルにして。
申し訳ございませんが、現在の設定では最小の解像度が1024×1024ピクセルとなっております。このサイズで全固体電池の図解画像を再度生成してもよろしいでしょうか?
現在、最小の解像度が1024×1024に設定されているようです。残念ながら、これ以上小さい画像サイズで出力することは叶わなさそうです。
生成できる枚数に制限あり
連続して画像を生成していると、以下のようなワーニングが出て画像生成ができなくなりました。
I apologize for the inconvenience. I was unable to generate images due to rate limits. Please wait for 5 minutes before generating more images. Once the time has passed, please let me know, and I’ll be happy to assist you further.
(ご迷惑をおかけして申し訳ありません。レート制限のため、画像を生成できませんでした。さらに画像を生成する前に5分間お待ちください。時間が経過しましたら、私にお知らせください。)
過度に連続で画像生成すると、過剰な負荷を回避するために制限がかかるようです。待機時間は、4分のこともあれば、長い場合は18分待ってくれと書かれることもありました。
ちなみに、生成時間も負荷状況によって変わっているようで、日本時間で休日の午前中に画像生成すると非常に速い一方で、夜22時ごろになると生成時間が2倍近く必要でした。
わかったことまとめ
遊び倒してみて、分かったことを以下にまとめておきます。
- 意図したテーマの画像生成ができる
- 4枚の画像が生成される
- プロンプトを複雑にするほど、4枚のバラツキは減る
- 色も意図したように指定できる
- 日本語の文字を含む画像生成は難易度が高い
- 英語であれば文字入りの画像も生成可能
- 生成した画像を修正する指示もできる
- 生成時間は、利用する時間帯で変わる
- 連続して生成すると制限がかかる(5分~20分)
- 生成する画像は1024×1024pxで1~2MB
DALL-E 3、噂されているとおり革新的な画像生成ツールです。これまでのDALL-E 2は生成のためにクレジットが必要でしたが、DALL-E 3はChatGPT課金 or Bingで使えるので、その敷居も下がっています。
業務で使うイラスト(詳細を無視できるような場合は特に)は、DALL-E 3で生成してしまうことで、わざわざ素材を探したり、自分で図解を作成したりしなくてよくなりそうです。
もっと面白い使い方がないか、今後も試行錯誤してみます。
関連記事

コメント