
近年「マテリアルズ・インフォマティクス(MI)」が、材料設計のための強力なツールとして登場している。
MIは、データサイエンス(機械学習など)を材料研究に応用することを指す。
本稿では、マテリアルズ・インフォマティクスの基本・事例と、まず何から始めればいいのかを述べる。
[ad]
マテリアルズ・インフォマティクスとは
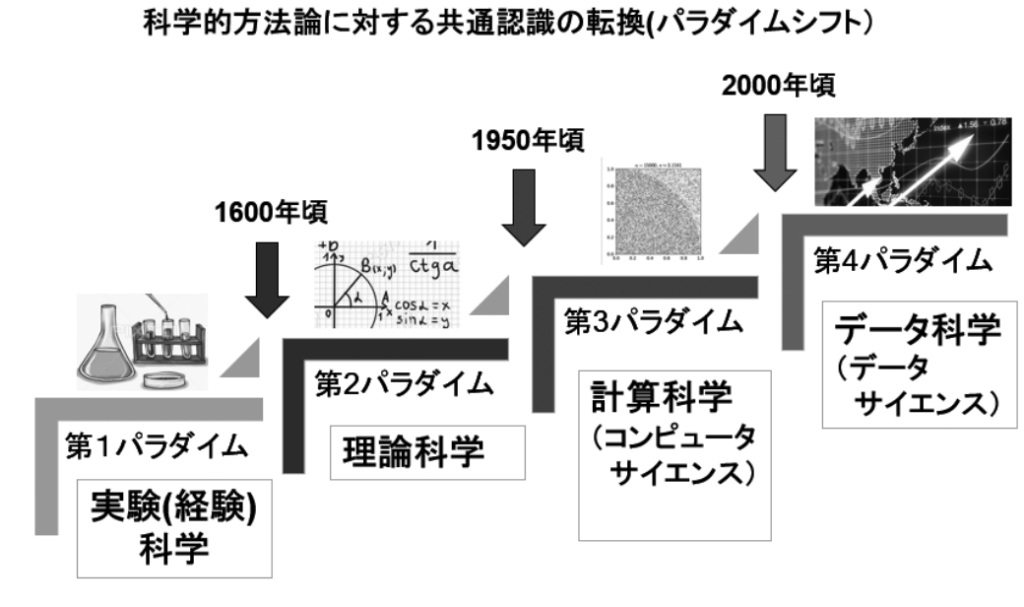
「マテリアルズ・インフォマティクス」とは、データサイエンスを材料設計に活用すること。
ご存じの通り、デジタル化により大量のデータが生まれている。
このビッグデータとデータサイエンスを組み合わせることで、
・自動運転
・来店者予測
など数多くのイノベーションが起こっている。
材料開発においても、いままで試行錯誤で行われてきた研究が、データの力によってより短期間で可能になりつつある。
既に材料開発に使われている
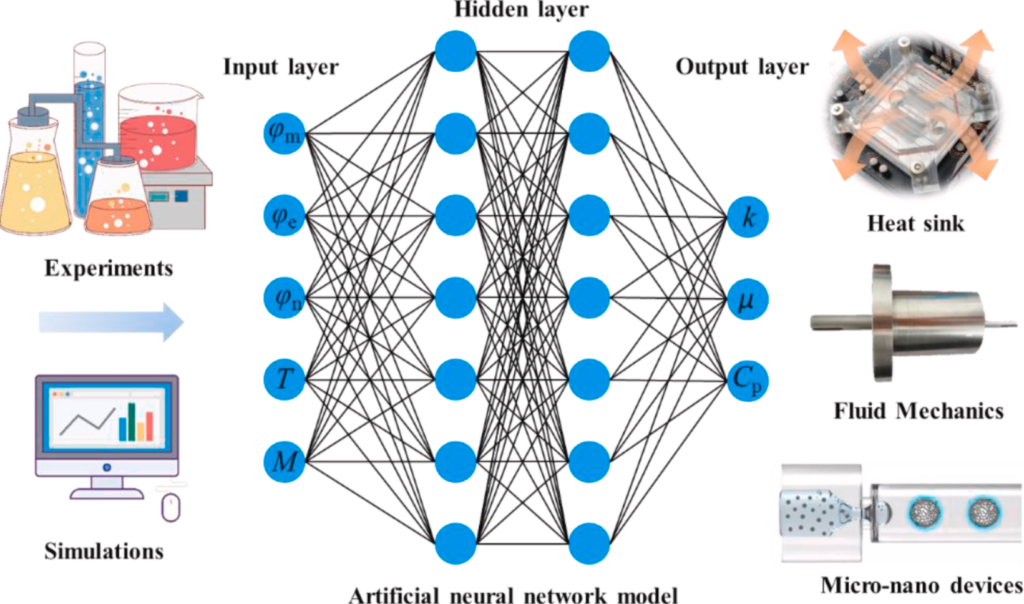
図:Machine learning and big data provide crucial insight for future biomaterials discovery and researchより
材料科学の分野では、マテリアルズ・インフォマティクスにより研究のあり方が大きく変わりつつある。
既に、マテリアルズ・インフォマティクスは、材料開発において、材料の発見やデータの解釈に大きな影響を与えている。
分野は多岐にわたり、熱電材料、強誘電体、電池の電極、水素貯蔵材料、高分子誘電体などの様々な分野で研究論文が発表されている。
データサイエンスの手法として、多変量統計解析、機械学習、次元削減、データの可視化などツールが用いられる。具体的な事例として、
・有望な電池材料のスクリーニング(材料選定)
・材料構造から物性(特徴量)を取得する
・テキストマイニングで論文から物性を抽出する
を以下で紹介する。
有望な電池材料のスクリーニング
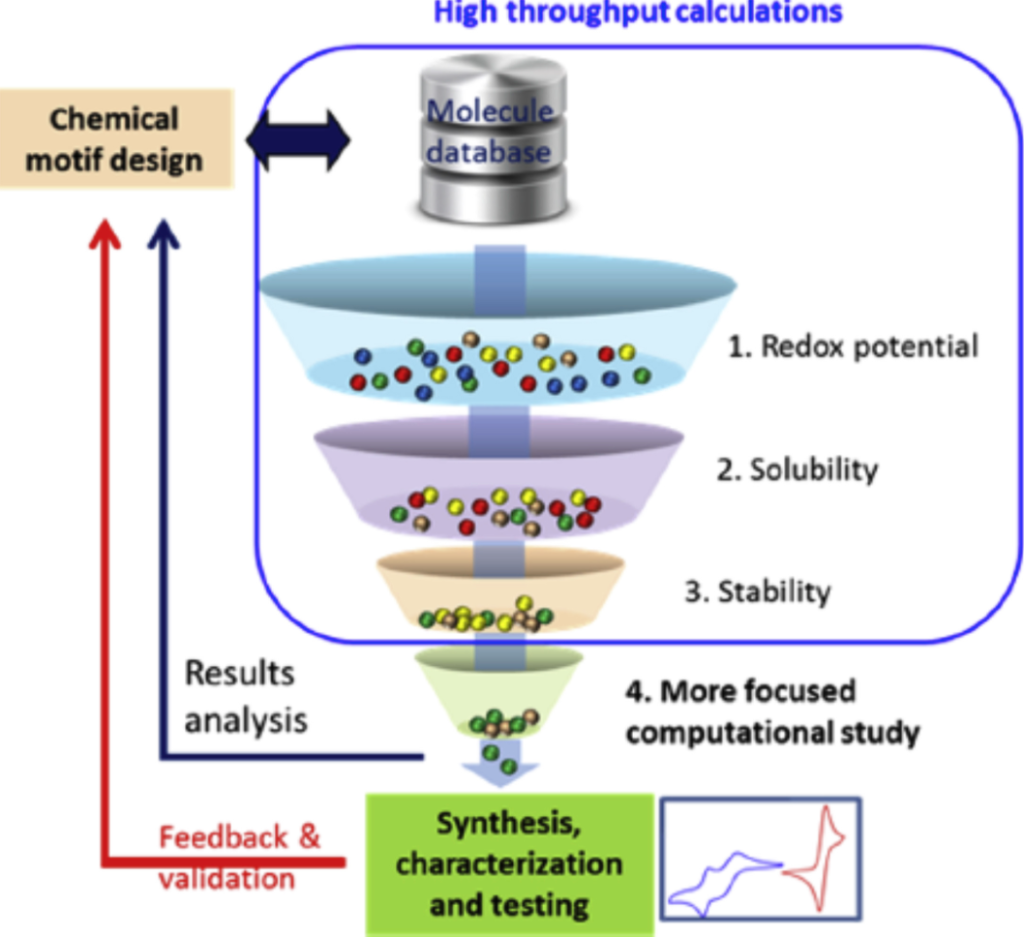
図:Accelerating electrolyte discovery for energy storage with high-throughput screeningより
世界中には大規模な”材料データベース”がある。
そのデータベースから、所望の物性値を満足する材料を選定することを試みている。
ここで取り上げた例は、非水系レドックスフロー電池において、1,000種類以上の材料から望む物性を持つ材料を抽出している。
酸化還元電位、溶媒和エネルギー、構造安定性の特性が目的を満足するようにスクリーニング(フィルタリング)して、候補物の材料を絞り込んでいる。
材料構造から物性を取得する

Parsing abnormal grain growthより
材料開発では、微細構造を電子顕微鏡などで観察し知見を得ることが多い。
上の写真のようなアルミナの結晶の観察像のうち、性能が良いもの、悪いものの”特徴”を抽出する試みが行われている。
重要な微細構造の特徴を捉えた”特徴量”を、マテリアルズ・インフォマティクスの分野でフィンガープリント(=指紋)と呼ぶ。
フィンガープリントのマップを作成することで、狙っている材料特性に対して、どのようなフィンガープリントであれば達成できるか逆解析が可能となる。
テキストマイニングで論文から物性を抽出する
論文には掲載されているものの、データベース化されていない材料データも存在する。
論文からデータを抽出する方法として、テキストマイニングが用いられている。
テキストマイニングが機械学習手法であるかは議論のあるところかもしれないが、データベース構築に役立つ活用方法であることは間違いない。
マテリアルズ・インフォマティクスの課題

マテリアルズ・インフォマティクス手法を適用しようとする研究者がよく行きつく課題は、
・統計やコンピュータの知識の不足
・材料知識の不足
・データセットの管理ができない
である。
統計やコンピュータの知識が必要
まず、インフォマティクスの手法の多くは、統計学や数学の背景で語られる。
そのため、材料技術者がマテリアルズ・インフォマティクスを使いこなすには、統計学やコンピュータサイエンスの専門知識が必要であるうえに、必要な知識を習得するために相当な時間が必要となる。
材料の知識が必要
一方で、統計に秀でた技術者(いわゆるデータサイエンティストなど)がマテリアルズ・インフォマティクスを扱う場合には、逆に材料の深い知識が必要になる。
理想的な材料の調合量はインフォマティクスで予測できても、そもそも材料が調合可能なのか、背反はないのか、毒性はないのか、など材料特有の知識(ドメイン知識)が必要になる。
つまり、材料と統計の知識をどちらも持ち合わせている人材が必要となる。
個人的な意見だが、材料技術者が統計を学ぶことが有益であると考える。材料の知識は学問的に学べるものというより、実際に調合・合成してみて初めて理解できることが非常に多い。
材料研究は、現象を物理的に説明できるものの方が少なく、技術者が長年かけて培ってきたカン・コツが重要になる。
情報技術の専門家が材料研究を学ぶには時間が掛かりすぎるため、材料技術を理解している人が情報科学を学んだ方が手っ取り早いと考える。
(必然的に、MI人材は材料系のバックグラウンドを持っている人が多い)
データセットの管理が必要
スキルはともかく、最も根が深い問題が”データの収集と管理”と言える。
マテリアルズ・インフォマティクスに利用するデータセットは大規模であることが望ましいが、場合によっては、比較的小規模で異質な限られたデータから、最大限の情報を引き出すことを目的としている研究もある(実際には、少ないデータ点しか得られず、否応なく小規模データセットを用いている事が大半と思うが)。
これらの小さな次元のデータセットは、局所的な実験点であることが多く、大局的に見たときに本当に最適解を見つけられるような予測精度が得られない。
それにもかかわらず、近年、研究者たちはマテリアルズ・インフォマティクスを利用して小さなデータセットから洞察を得ようとしている。小さなデータセットで機械学習を適用することは、オーバーフィッティングの危険性やそれに伴う予測能力の低下など、一定のリスクがあることに注意したい。
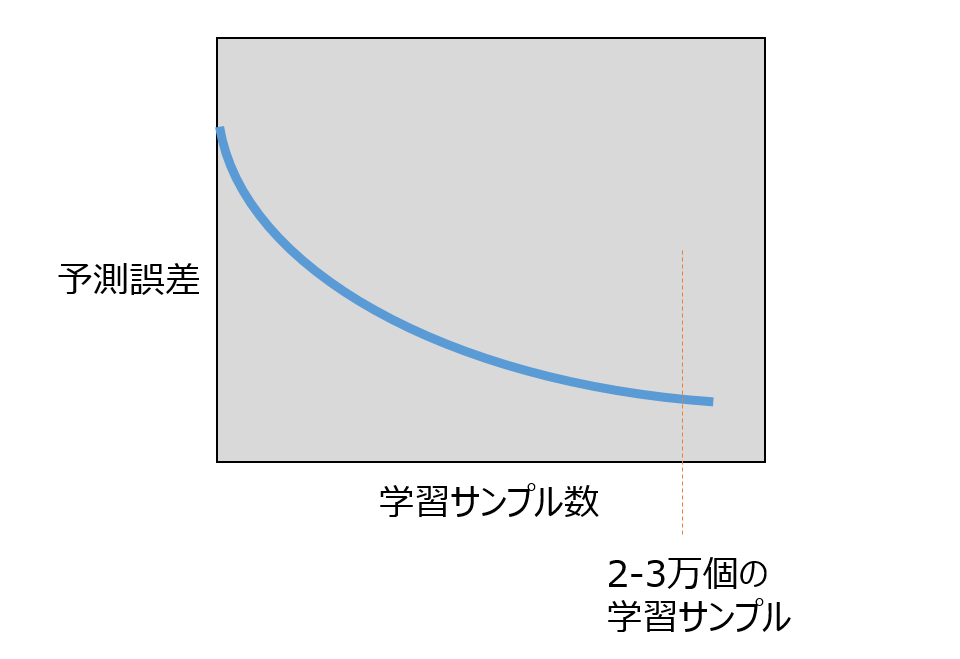
実際、予測の精度に対するデータセットサイズの重要性は評価されており、密度汎関数理論(DFT)と機械学習を組み合わせた固体の熱力学的安定性の計算において、原子あたりのエネルギーを正確に求めるためには、約2万〜3万個の学習サンプルが必要とされている。学習セットのサイズが大きくなるにつれて、予測誤差は緩やかに減少する。
また、実験的に得られたデータと計算から得られたデータを組み合わせることで、データ数を増やすという事も検討されている。
既存のデータは、パラメータ空間(組成など)の特定の領域に限定されていることが多く、また、計算データの場合には、狭い範囲のシステムでしか利用できないこともある。
いずれにせよ、より最先端の材料に対しては、手元で得られた少ないデータで学習せざるを得ないのが現状であり、取得したデータの整理と蓄積が直近の課題と言える。
より発展的な材料開発
より発展的な材料の開発という意味で、統合計算材料工学(Integrate Computational Materials Engineering:ICME)を紹介したい。(必ずしもこのような呼ばれ方がしているとは言えないが、材料開発のトレンドはICMEの方向に向かっている)
材料開発の分野では、以下の3つを統合したものをICMEと呼んでいる。
・モデリング(数式にする)
・シミュレーション(特にマルチスケール計算)
・材料データベース
シミュレーションでは”マルチスケールモデリング”が重要となる。
mmオーダーの部品レベルのスケールと、nmレベルの材料構造(多結晶材料など)をどちらも反映することで、より高い精度で、製品性能まで含めて予測可能にすることで、より素早く製品開発に貢献しようというもの。
特に材料開発は足が長くなりがちなので、ICMEを活用して開発サイクルを短くすることが期待されている。
なによりデータ管理から始めるべき
データはマテリアル・インフォマティクスの中心にあるため、今後マテリアルズ・インフォマティクスを活用しようと考える研究者にとって、データ管理が重要な検討事項となる。
つまり、機械学習を学ぶより先に、ずさんなデータ管理を改善する方が先決と言える。
データ収集と管理を併せてキュレーションと呼ぶ。
どういう日に、どういう湿度で、どういう風に混ぜて、といったプロセスも加味してデータを蓄積していくことで、「有用性があり、材料のライフサイクルを通じて取得されたデータの継続的な管理」が可能となる。
キュレーションは、データの作成、分類、検証、保存など、いくつかのタスクから構成される。一般的なビッグデータの管理と考えかたは同じで、これなどが参考になる。
全人類が材料データを共有できるか?
世界中であらゆる研究者が日々材料データを取得している。材料データを共有することについても議論が為されているが、大きく3つの問題がある。
データの所有権と共有
所有権の問題を考慮した上で、どのようにしてデータの共有を促進するか?データのメンテナンスには誰が責任を負うのか?
メタデータ・キュレーション
メタデータとは、別のデータセットを記述するデータセットのこと。適切なメタデータの記述方法は何か?メタデータの保存と蓄積のための最良の方法は何か?
複数のソースからのデータの管理
複数のソースから得られた異質なデータ(データ・シーケンス、グラフ、顕微鏡写真、パターンなど)にどのように対処するのが最適か?異種データを様々な分野の実務者に役立てるにはどうすればよいか?
上記は議論が尽きないところであり、今後も調査が必要だろう。
書籍で学ぶ
ここまで、少しアドバンストな内容も含めて書いてしまったため、初心者が理解できるような書籍を紹介しようと思う。

マテリアルズ・インフォマティクス-材料開発のための機械学習超入門
MIについて書かれた初心者向けの書籍で、比較的早い時期に発売されたもの。
これ一冊でMIが出来るようにはならないが、概要を理解するにはよくまとまっている。

Orange Data Miningではじめるマテリアルズインフォマティクス
こちらはより実践的な内容の書かれた書籍。
Orangeというツールキットを実際に動かしてみて、機械学習を学ぶもの。新しい書籍であるため、より情報がアップデートされており、中級者におすすめ。
マテリアルズ・インフォマティクスの分野は、研究が始まったのは50年以上前だが、深層学習の発展と機械学習ブームに乗ってトレンドとなってきた。
それゆえに、未だに試行錯誤の状態にあり、今から着手してもすぐにキャッチアップできる分野でもある。
今後も動向を調査していきたい。
コメント