
私は日々1時間近くかけて通勤している。
通勤時間は、Youtubeで動画を見ながらダラダラと時間を潰しているのだが、最近、興味深い動画を見かけた。
安宅というおじさんのプレゼンである。2018年に行われたもののようだ。
このおじさん、かなり有名な人で、神経科学のポスドクやらマッキンゼーでのコンサルやらを経て、現在はYahoo!CSOでありながら慶応のキャンパス(SFC)で研究室も持つ。
プレゼンでは、 迫りくるAI×データ時代にについて話している。
動画で興味を持った私は、この人の著書「シン・ニホン」を購入し、2週間かけてじっくり読んだ。437ページの超大作だ。
「シン・ニホン」は、未来の日本はこうあるべきだ、という提案がなされた本だ。AI×データ時代で必要なスキルセット、人をどう育てるか、日本がどう進むべきか、まで、データを用いて議論されている。(正直、書籍の内容は安宅氏のプレゼンを詳細に説明したもので、ざっくりした方向を理解するためにこの本を読む必要はない。)
安宅氏の講義動画も一通り視聴した。講義、プレゼン、書籍で内容の重複しているところは多いが、それゆえに記憶に残った。
安宅氏は常々、未来は予測するものではなく、自ら作り出すものだ、と話している。安宅氏の目指す未来が「シン・ニホン」であり、その未来に向けて国に働き掛けている。つまり、「シン・ニホン」を理解する事で、少しは未来の事がわかる。
私は自動車産業に従事している。自動車はオールドエコノミーでありながら、AI×データ時代に最も影響を受ける産業だ。自動運転、シェアリング、OTA。AI×データ時代において、どのようなスキルやマインドを持った技術者になるべきなのか。シン・ニホンを読んだうえでの、自分なりの考えを記したい。
※本記事は「シン・ニホン」の要約ではなく、筆者の所感である事を理解頂きたい。
どんな時代が来るのか
AIの普及で、ビジネスの形は変わる。データ×AI活用の基本ループ(系)のパフォーマンスを見ながらチューニングすることが業務の中心になる。
ビジネスモデルとしては、aiboのような、データを集めて性能が向上し、サービスの価値が上がり、事業者は継続して利用費を回収できるモデルが主力となる。つまり、販売後のサービスで収益を上げるモデルが普通になり、各事業者は顧客へのコミット期間が長くなる。
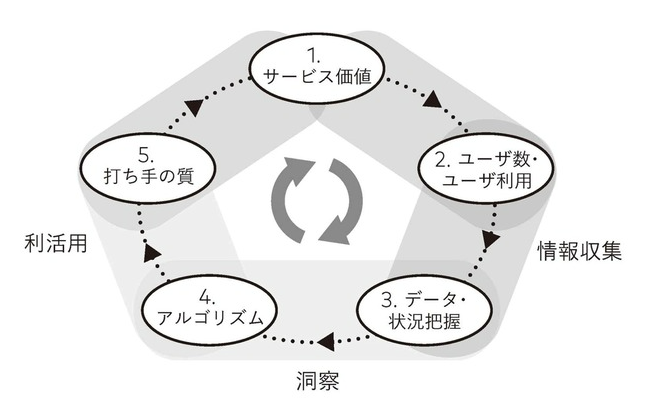
【データ×AI活用の基本ループ】
1.サービスの価値があがる
2.ユーザが集まる、利用が増える
3.データが増え、状況把握が進む
4.アルゴリズムの性能が上がる
5.打ち手の質が上がる
データ×AI時代のビジネスモデルは、先行者利益が効きやすい構造に変化する。つまり、さっさと始めた方がいい。
アルゴリズムの性能はデータが増えれば勝手に上がるので、これまでのような人間の試行錯誤によるPDCAサイクルは半ば終演する。
自動車で言うならば、自動運転車のエラーデータが蓄積され運転精度が向上することで、サービスの価値が上がり皆が利用するようになる。安全も大切だが、データを握る意味でも、自動運転は早期投入も欠かせない。
ビッグデータとは

データの種類には3つある。
①調査データ(リサーチデータ)
②実験データ
③ログデータ
近年、ビッグデータとして注目されるのは主に③ログデータで、スマートフォンの普及などで大量に取得できるようになってきた。だが、ログデータだけで分析を行う事は容易ではなく、実験データやリサーチデータを併用しながら分析を行うのが普通だ。
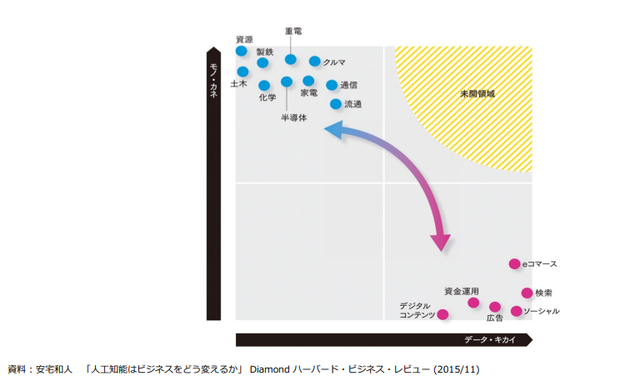
これまでの産業は二極化だった。モノカネがあるか、データ・キカイがあるかのどちらかだった。
一方、この2020年~2040年にかけて、上の図でいうところの、モノ・カネと、データ・キカイを両方扱う「未開領域」に近づいていく。トヨタがデータ収集を始めたり、Googleが自動運転車のハード(LiDARなど)に手を出したり、といったことだ。
ビッグデータ×AIにおいて、リニアな思考では読み違える。横軸を時間とおくなら、縦軸はログスケールで考えるべきだ。大半の人が思っているより遥にはやく変化は起きる。
今は産業革命並みの変化の渦中にいる。インターネット初期の1990年代と同じ、すごく面白い時代が来ようとしている。 ICTとそれ以外とかではない。全ての産業がデータ×AI化する。
ただ、日本の政策や大企業は、このデータ・キカイの世界に投資していなさすぎる。
日本の大企業の立ち位置
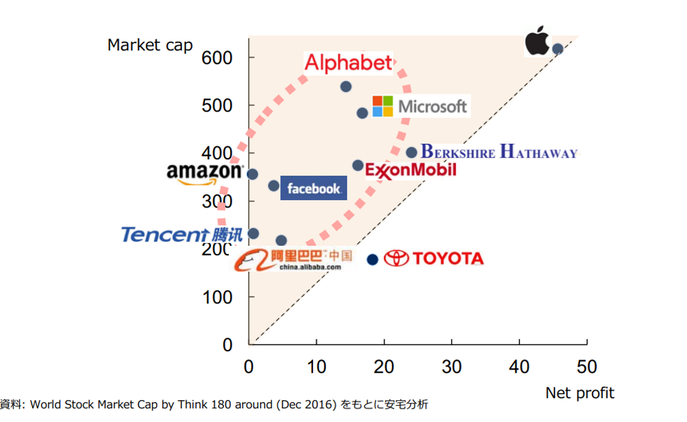
日本の経済力(=国力)を上げる必要がある。なぜか。世界に対して日本の影響力を維持する必要があるためである。
経済力は、企業の価値(=時価総額)そのものである。2000年ごろまでは、利益(=Net profit)の多さが企業価値に繋がった。大きな純利益を生み出す企業は、自動車で言えばトヨタなどがそうだ。20億ドル規模の利益をたたき出している。
2000年頃まで、利益をn倍化の理論で増やすのが主流であった。自動車販売がn倍になれば、利益がn倍になるという考え方である。しかし、この20年で時価総額を決めるルールが変わった。
これからは「世の中を変えてる感」が事業価値になり、時価総額に繋がる。実に曖昧な指標であるが、テスラが世界2位のマーケットキャップ(時価総額)を持つ企業となったのが最たる例で、富の生まれ方が劇的に変わっている。
n倍化ではこの先勝てない、という前提を本当の意味で理解する必要がある。つまり「n倍化」を実現するために作られた事業、R&D、サイエンス、人、教育を、全て変えるべきである。
日本の現状

現状の日本は、鎖国していた日本と同じ。国として競争力の源泉となるのは
・データがたくさん獲れる
・処理力
・回す人(人材数)
この3つだが、ビッグデータ系の技術は英米およびイスラエルに集中している。
論文は米中の2強。日本の人材は、大卒理系が2割しかおらず少ない。つまり、源泉3つは現状いずれも無い。

今後のAI×データ時代はどう進むのか。鎖国時の産業革命は、3フェーズで進んでいた。
フェーズ1.技術の登場
フェーズ2.技術の実装
フェーズ3.技術の組み合わせとエコシステムの誕生
今起きているAI×データ時代の変化もこの3フェーズで行われる。
1のフェーズはほぼ終わった。鎖国時代と同じく、日本は2000年~2020年の間でフェーズ1に完全に乗り遅れた。
次に来るフェーズ2は、確実に仕掛けに行くべきであり、フェーズ2に乗ろう!というのが、政府が主導しているsociety5.0である。
日本はフェーズ2で戦える
フェーズ2では、技術の繋ぎ合わせで世の中の課題を解決していく。様々な技術をマッシュアップ的に使う。APIをフル活用し、共通技術は他所を利用して、コアは自社でやる。
日本は出口側の各産業ドメインでデータを手にしている(あるいは手にできる環境にある)ため、フェーズ2はまだ戦えるはずである。また、世界中が技術が大きく進歩して産業が成長しているのに、日本はこの20年成長しなかったので、伸びしろは相当大きい。

フェーズ2は、課題に対して「できたらいいな」を妄想して実装するフェーズである。
この国は、妄想が得意だ。3歳ごろから英才教育されている。「ドラえもん」に代表される漫画の類だ。暗記パン、どこでもドアのようなSFを全部実装していけばいい。フェーズ1で生み出された技術を世界からパクって来て、世の中に必要なものを実装していく。
AI vs 人間 は起きない
よく議論される「AIが仕事を奪う」は結局、人間同士の戦いに過ぎず、AIやデータの力を使わない人間が淘汰される。
AIやデータの力を使う仕事の仕方は、馬に乗ってる感じ。なにか間違えたらしばく。人間がほかの生き物を飼うような時代。仕事もそうなる。しばく側にまわる。レベル2以上の自動車に乗ってる人はわかると思う。基本はAIが動かして、ちょっと間違えたら修正を入れる。
求められる人(概念)
今後、AIによってデータを回す作業は全て自動化され人の手を離れる。人間の仕事は見立てることであり、決める事になる。これまでとは違って、覚えるよりも、自ら考えて生み出す人が必要になってくる。基礎研究より、課題にエキサイトして実装することに興味を持てる人が必要。
必要な人物像は、夢を描き、複数の領域を繋いで形にしていく力を持っている人。
交換可能な部品になると厳しい。人が群がる場所は、コモディティになるということ。同列の中での優秀さより、質的な違いが価値になる。
日本には、ビジネス課題と新しい技術をつなぐ人がいない。「妄想して形にする力」が大切。
専門家もおらず、しかも専門家(ヲタク)は実社会の課題に興味がない(技術を磨くことしか興味がない)。ヲタクではなく、ハッカーが必要。
求められる人(スキル)
ICT業界の海外大手から「日本は最もデータ×AI人材が手に入らない国」「日本だけ基準を下げないと人が採れない」と言われている。
日本にはSIerはある程度いるが、自然言語処理や機械学習などの研究・実験環境を、堅牢で大規模かつリアルタイムの本番環境に繋げられる人材が足りていない。高速データ収集、分散環境、ロギング周りの仕組みを作れて回せる人も極めて限定的。
AI×データ時代では、マシン的なスキルにはさして意味がない。
マシン的なスキルとは、データを記憶する、高速で計算する、などの、マシンの方が長けているスキルのこと。
それよりも、AIにはできない、気づき(=自分の中にある何らかの知識や理解が、異なる何かと繋がること)をどれだけ得られるかが、人間には求められる。
これは「知覚」であり、ある種の生命力であり人間力である。
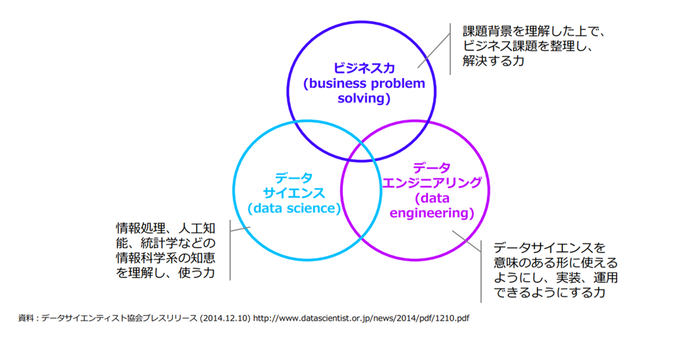
データから気付きを得るために必要なスキルは、
・データサイエンス(情報処理・人工知能)
・データエンジニアリング(実装力)
・ビジネス力(ドメイン知識)
実際のプロ現場においては、このどれかに軸足を持ち、3つの領域いずれもミニマムレベは持った状態に人がチームを組みことで補完しあっているのが普通。
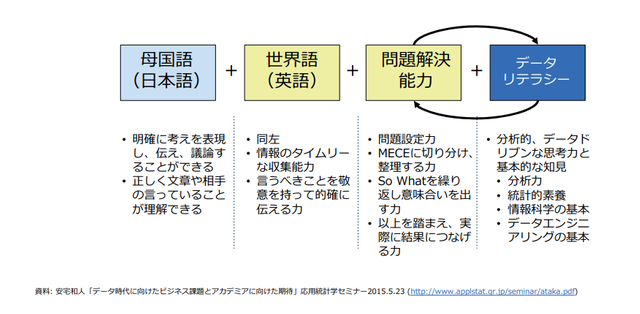
リベラルアーツ(基礎教養)も大きく変化している(6。これからの読み書きソロバンである。
AIを使う側と搾取される側を分けるのは、このリベラルアーツを認識しているかどうかで決まる。
AI×データ時代のリベラルアーツ=
母国語+世界語(英中)+問題解決能力+AIデータリテラシー
世界語(英語と中国語)は必要。英語できるかできないかで、収入レベルは倍に変わる(と本書には書かれているが、倍は言い過ぎなのでは)。
日本はエコノミー的には縮小局面なので英語は必須。自動翻訳が普及するといっても、グローバルでネゴするような立場の仕事を迫られることを考えると、相手の表情や間のようなものを読むためにも、英語は必須。
日本は、米国が同盟で、中国が地理的に近い。世界最大の市場が身近にあり、チャンスは多いので、積極的に英語・中国語は習得しておくとよい。
統計的なセンスが最も大切で、次いで線形代数や微積がわかる必要がある。
なんでもできるのはすごいが、これからの時代はもう無理。自分が得意なことと全然違うことにディープに詳しい友人を幅広く作るべき。同じ業界で友達を増やしても、価値が生まれにくい。友達がどれだけ異質な業界で持てるかが大事。頼れる人を作るためには、自分が魅力的である必要がある。
問題解決の考え方
上記のようなスキルセットは必要だが、本当に大事なことは問題解決の考え方だ。
技術に逃げない。極論、技術は道具なので誰でも使える。一体、なんのためにやるのかに極力フォーカスする。問題解決の考え方に極力フォーカスする力を鍛えるべきだ。
データ×AI時代の問題解決の練習方法として、下記のようなものを挙げられている(安宅氏はこれを初等・中等教育で行うべきとしていた)
①その現象をパターンにわける
②背景のルール、要素、階層構造を読み解く
③知覚した内容を図などでアウトプットする
④違う視点で見てみる
⑤なぜ?を繰り返す
この問題解決の考え方は、トヨタ式問題解決に非常に近いと感じる。ギャップフィル型の問題解決で、これを習得し、次第にビジョン設定型の問題解決にトライしていく。
教育の手順
AI×データ人材を育成する(あるいは自身がそうなるための)教育は、以下のようなものが考えられる。
①身の回りのデータを取る
教育で扱うデータは、適当に作られたものでも悪くないが、味気ないため興味を持たせにくい。身近な人の行動に関するデータなら、気になって積極的に取り組もうとしてくれる。
②データを見る方法を学ぶ
身近なデータからパターンを見つけ、機械に学習させる。
データから課題をみつけて、ソフトウェアやハードウェア使ってどのように課題を解決できるかを考える。
③ソフトウェア作りを体験する
ソフトウェアづくりといっても、JavaやPythonなどのコーディングをしろとは言わない。課題解決に必要なものを学べばよく、micro:bitなどの簡単なツールで解決するのであれば、それでよい。
④ものづくりを体験する
実世界の課題を解決するためにハードウェアが必要であれば、ものづくりもやってみる。汎用的な機械部品を購入して、RaspberryPiなどで繋いで実装してもいいだろう。
これらを一通り経験しておけば、「妄想して形にする力」の基礎は身に着くのではないか。おそらく、これらをやっていくうちに、より高度な事がやりたくなるだろう。
政府がやるべきこと
シン・ニホンの第5章「未来に賭けられる国に」は、これだけで本一冊書ける内容だった。
論点は、日本の財布からどこに金をだすのか、しっかり未来を見据えて議論すべきだ、ということ。具体的には、教育・科学技術予算の割合を増やす(それも数%)ことを提案している。
安宅氏は、年間2兆円で未来は変わると言っている。社会保障給付金120兆円と比べれば2%以下。普通のマネジメントをしていれば良いレベルとのことで、この部分の理解者を増やしたいためにこの本を書いたのだろうと受け取った。
Twitterでよく見る、大学にはお金がない、ということもしっかり書かれている。今後、研究者の待遇改善が図られる事を願う。
まとめ
これからの技術者が必要な能力は
・AI×データ時代のスキルとリベラルアーツ
・データから知覚する
・妄想ドリブンで世界を描く
・複数の領域をつないで形に出来る
・どんな話題でも相談できる人を知っている
といったところ。
今まだこの能力が身についていない人は、少なくとも時代の変化より早く行動し身に着ける事が求められている。
コメント