
Kaggleを始めてみました。
Kaggleは主にデータサイエンスを用いた予測モデルの精度を競うプラットフォームで、いわゆるデータサイエンティストが注目され始めた昨今、盛り上がっているコンテンツです。
私も、初心者ながらこの2ヶ月ほどで、昔のコンペに挑戦してみました。
目標
今回、過去コンペのディスカッションやコードは参照しつつも、コードを丸々使うのではなく、自分で0から書いてみるということをトライしました。
最初はみんな大好きKaggle本のコードを参考にしつつ、Pandas本とネット検索を駆使してコーディング。該当カーネルは下記にありますので、よければUpVoteをお願いします。
https://www.kaggle.com/mnthasi/recruit-restaurant-01-pre
昔のコンペをやり直すことの特徴として
・すでに公開notebookがある
・自分はランキングには載らない
・もちろんメダルなどの獲得はできない
など、メリットもデメリットもあるのですが、過去コンペの上位者のソリューションを学ぶと強くなれると聞いたので、まずは過去コンペから挑戦です。
コンペ概要
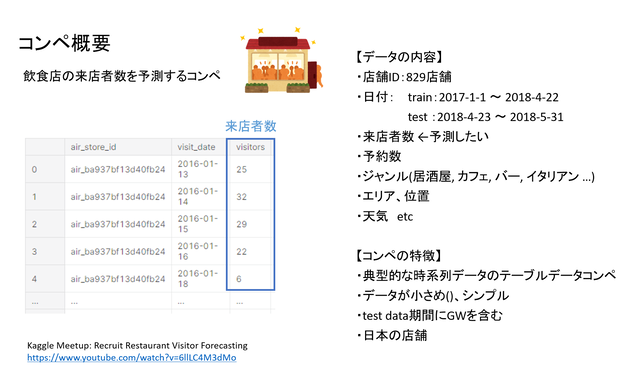
挑戦したのはRecruit Restrant Visitor Forcastingというコンペです。これは、日本のリクルートが主催していたコンペで、飲食店の来店者数を予測するというもの。
データは比較的シンプルで、テーブルデータのみで構成されており、データ数も数十万とそこまで多くありません。ただ、テーブルがいくつものファイルに分けられているという点が厄介でした。
店舗は829店舗、期間は2017年初頭から2018年4月までがトレーニングデータで、2018年5月がテスト期間でした。
トレーニングデータには、店の予約者数、ジャンル、エリア、位置、天気などが含まれます。
私の解放はざっくり下記の通りです。
・LigjhtGBMを用いた週ごとモデル
・特徴量としてラグ特徴量を利用
・統計値とLightGBM結果をアンサンブル
特徴量設計
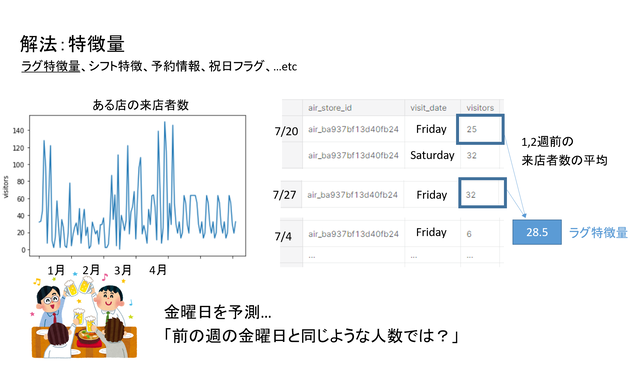
まず特徴量については、Kaggle本などでも時系列データの特徴量エンジニアリングの一つとして紹介されている「ラグ特徴量」を利用しました。
金曜日の来店者数を予測するためには、その前の週の金曜日の来店者数を参照すれば良いのでは?というアイデアから、何週間も前まで遡って来店者数を引っ張ってきて、平均をとって特徴量とするものです。
のちにモデルに対する寄与度の話でも出てきますが、この特徴量は非常に効きました。
モデル概要

モデルは、LightGBMを週ごとに分けていました。
テスト期間の1週目はラグ特徴量として前の週の情報を使えるが、2週目は前週がテスト期間のため前週データを利用したラグ特徴が使えないためです。
そのため、ですと期間の6週全てに対してモデルを別々に作成しました。
アンサンブル
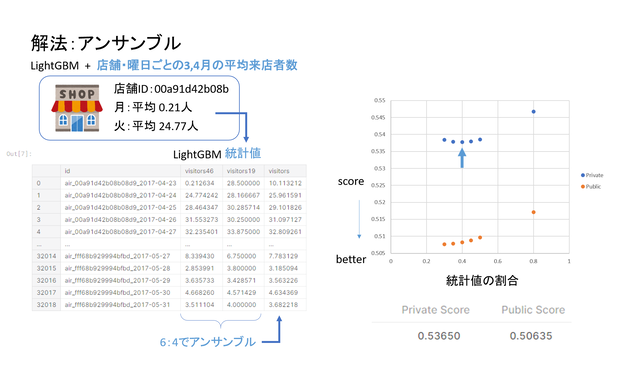
最終的なサブミッションには、LighjtGBMの結果と、各曜日、各店舗ごとの平均来店者数とを6対4でアンサンブルしました。過去のコンペティションでは、サブミットした瞬間にプライベートスコアまで開示されるので、アンサンブルの最適値がわりますので、トライアンドエラーをくり返しました。
解法まとめ
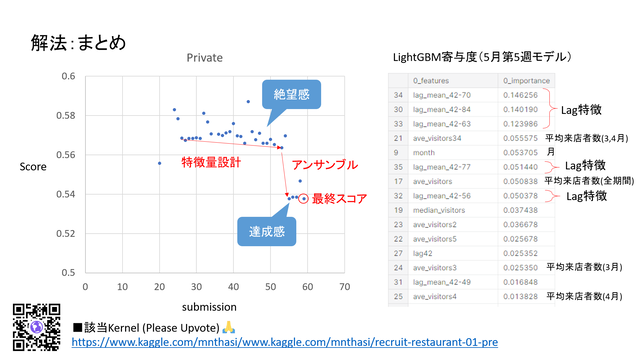
このようにして出したスコアは0.539。ですが、当時のランキングの上から数えて半分くらいだったので、まだまだ修行が必要です。
初めてコンペティションを0からやってみて、学びが多くありました。・初心者でも楽しい・Kaggleに高性能パソコンはいらない・やってみると難しい(わかるとできるは違う)・最近はtableデータだけで戦えるコンペは少ない?・パラメータチューニングでの精度向上には限度がある・モデル変更、複数モデルのアンサンブルが必要・過去のCodeをたくさん読むので勉強になる
私のまとめ資料は以下の通りです。もしご興味あればご覧ください。
コメント