
テーブルデータを用いた、値の予測のためによく用いられる勾配ブースティング木。今回は、XGboostを用いて、簡単なテーブルデータに対して予測モデルを作ってみたので紹介します。コードはpythonです。Kaggle Codeへのリンクはこちら。
ライブラリをインポートします。
import pandas as pd
import numpy as np
from xgboost import XGBClassifier as XGB
import seaborn as snsランダムに生成した数字を持つ500行のDataFrameを作成します。
np.random.seed()
# 中に入れる値を作る、index = 10, columns = 4
val = np.random.randint(0,100,size=2000).reshape(500,4)
columns = ["A","B","C","D"]
data = pd.DataFrame(val,columns = columns)
data
ランダムに生成したテーブルデータの概要を把握します。
data_all.describe()
テーブルデータを、教師データ(train)とテストデータ(test)に分けます。
train = data_all[:400]
test = data_all[400:]それぞれについて、目的変数(_y)と、説明変数(_x)に分けます。
# 学習データ
train_x = train[["B","C","D"]]
train_y = train[["A"]]
# テストデータ
test_x = test[["B","C","D"]]
test_y = test[["A"]]Xgboostのモデルを定義します。
# モデルを定義
Model = XGB(n_estimators=100, random_state=71)学習の実行
%%time
Model.fit(train_x, train_y)テストデータに対する予測を実行します。
pred = Model.predict(test_x)
pred予測した値と、実際の値を比較します。
comp = pd.DataFrame()
comp["actual"] = test_y.A
comp["pred"] = pred
plot = sns.scatterplot(x=comp['actual'], y=comp["pred"])
plot = sns.scatterplot(x=comp['actual'], y=comp["actual"])
plot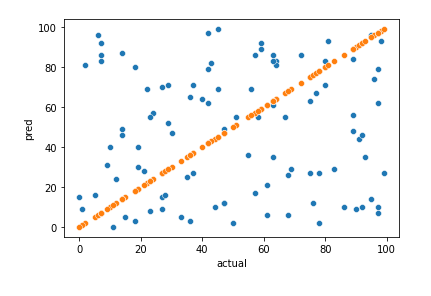
今回はランダムな値を用いたので、予測精度は出ません。実際のデータに置き換えてみて、このモデルを学習させてみるとよいと思います。
https://www.kaggle.com/mnthasi/210513-xgboost-prediction-japanese
コメント