【実践python】AIによるCAEサロゲートモデルの作り方にて紹介した、LightGBMでサロゲートモデルを作るコードの詳細を説明します。
コードは以下にもあります。コピーしてご自身で計算をすることもできますので、ぜひ試してみてください。
https://www.kaggle.com/mnthasi/lightgbm-cae
モジュールをインポートする
必要な以下のモジュールをインポートします。
・pandas:テーブルデータの取り扱い
・numpy:演算用
・lightgbm:機械学習モデル
・seaborn:可視化用
import pandas as pd
import numpy as np
import lightgbm as lgb
import seaborn as snsデータを読み込む
データを読み込みます。データは下記リンク先にありますので、必要であればダウンロードしてください。
https://www.kaggle.com/mnthasi/210718-cae-resultcsv
ご自身のファイルを利用する際は、必要に応じてファイルのディレクトリを書き換えてください。
data_all = pd.read_csv("../input/210718-cae-resultcsv/210718_cae_result.csv")
data_all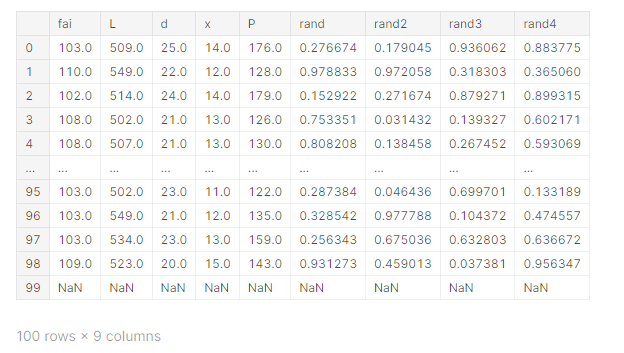
データの中身を確認する
ファイルの中身を確認します。今回のファイルの変数として利用するのは、
・設計変数:fai, L, d, x
・目的変数:P
とします。(rand1-4は無視して頂いて結構です)
data_all.describe()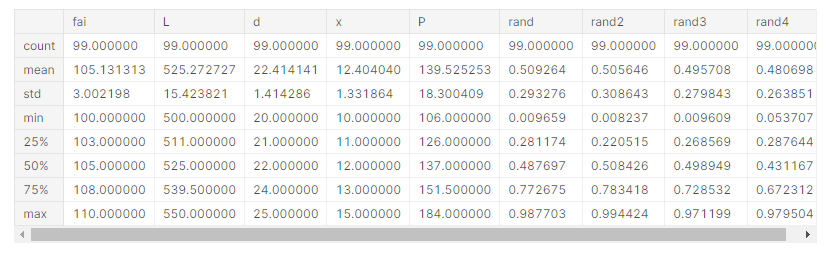
データを学習データとテストデータに分割する
データを、モデル学習用のtrainとテスト用のtestに分けます。前半80個のデータを学習用(train)、残りのデータをテストデータ(test)とします。
train = data_all[:80]
test = data_all[80:]設計変数と目的変数を分ける
さらに、train,testそれぞれについて、設計変数と目的変数に分けます。
# 学習データ
train_x = train[["fai","L","d","x"]]
train_y = train[["P"]]
# テストデータ
test_x = test[["fai","L","d","x"]]
test_y = test[["P"]]LightGBMのモデルを学習する
モデルを定義し学習します。
paramsで指定するのは、LightGBMのハイパーパラメータです。チューニングはしていませんが、私は経験的に初期値としてこれらの値を用いています。
%%time
params = {
"objective" : "regression",
"metric" : "rmse",
"num_leaves" : 40,
"learning_rate" : 0.01,
"bagging_fraction" : 0.8,
"feature_fraction" : 0.4,
"bagging_frequency" : 6,
"bagging_seed" : 42,
"verbosity" : -1,
"seed": 42
}
train_lgb = lgb.Dataset(train_x, label=train_y)
test_lgb = lgb.Dataset(test_x, label=test_y)
evals_result = {}
model_lgb = lgb.train(params, train_lgb, 10000,
valid_sets=[train_lgb, test_lgb],
early_stopping_rounds=200,
verbose_eval=1000,
evals_result=evals_result)[LightGBM] [Warning] Unknown parameter: bagging_frequency Training until validation scores don't improve for 200 rounds [1000] training's rmse: 6.63047 valid_1's rmse: 27.7497 Early stopping, best iteration is: [1332] training's rmse: 6.47568 valid_1's rmse: 27.705 CPU times: user 1.05 s, sys: 44.5 ms, total: 1.1 s Wall time: 304 ms
LightGBMでは、指定した評価指標を最適化するように、クロスバリデーションが行われます。
学習後のアウトプットを確認すると、RMSE=6.47で、Pを予測できるとわかります。
データに含まれるPのaverageが130、stdが18なので、RMSE=6.47はそこそこ高い精度で予測できているといえるのではないでしょうか。
モデルを用いてテストデータを予測する
テストデータを予測します。
pred_lgb = model_lgb.predict(test_x)
pred_lgb予測値と実際の値を比較する
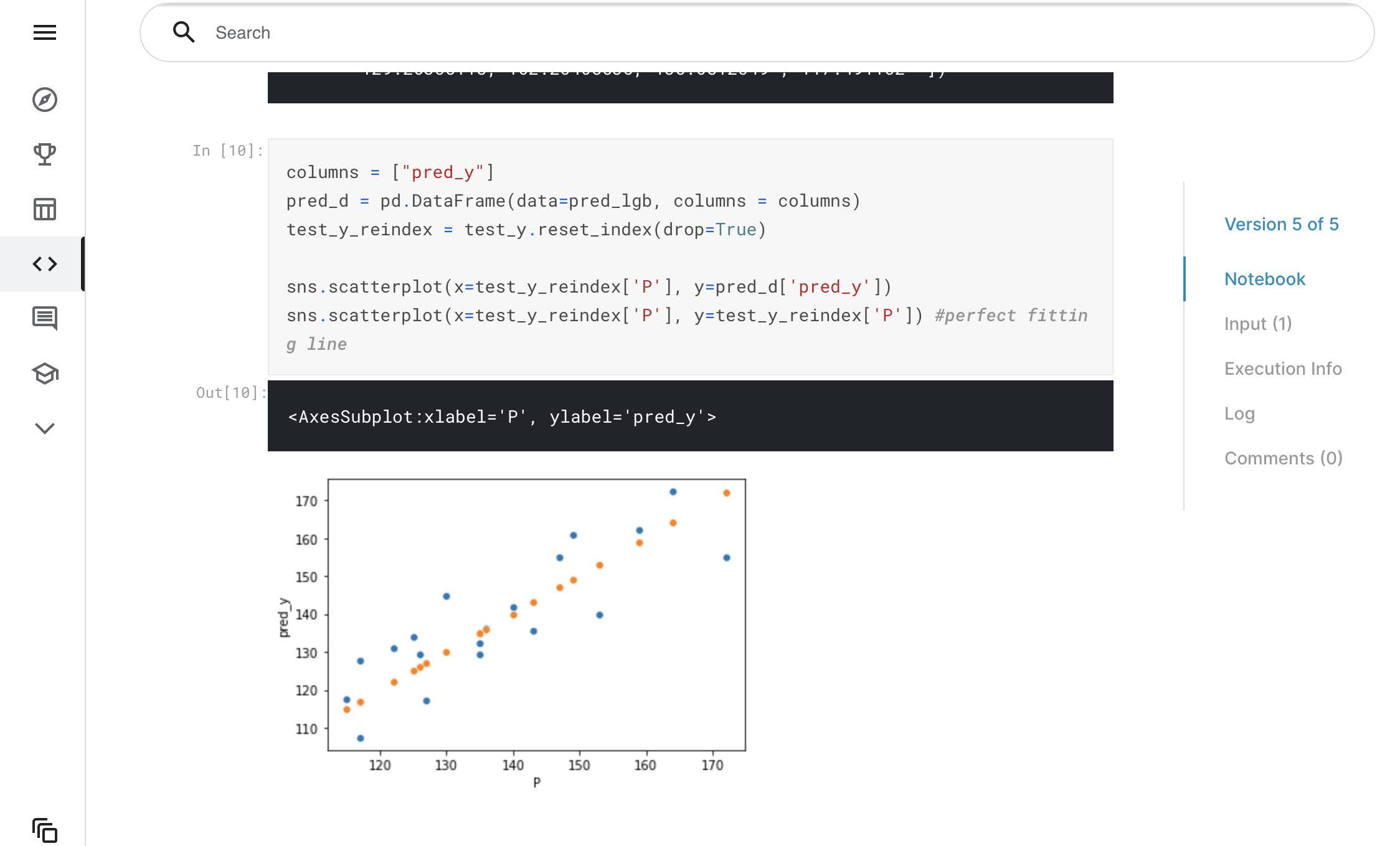
縦軸に機械学習モデルの予測値、横軸にシミュレーションの結果をプロットしたグラフを描画します。
columns = ["pred_y"]
pred_d = pd.DataFrame(data=pred_lgb, columns = columns)
test_y_reindex = test_y.reset_index(drop=True)
sns.scatterplot(x=test_y_reindex['P'], y=pred_d['pred_y'])
sns.scatterplot(x=test_y_reindex['P'], y=test_y_reindex['P']) #perfect fitting line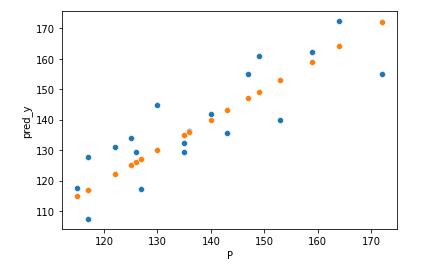
オレンジのプロットが、シミュレーションの結果を機械学習(サロゲート)モデルが完全に予測できた場合です。
対して青色のプロットは機械学習の予測結果で、一部外れているもはあるが、比較的良好な予測精度であるといえます。
特徴量の重要度を算出する
# 特徴量重要度の算出 (データフレームで取得)
# 特徴量名のリスト(目的変数CRIM以外)
# 特徴量重要度の算出方法 'gain'(推奨) : トレーニングデータの損失の減少量を評価
cols = list(train_x.columns)
cols_df = pd.DataFrame(cols)
# 特徴量重要度の算出 //
f_importance = np.array(model_lgb.feature_importance(importance_type='gain'))
# 正規化(必要ない場合はコメントアウト)
f_importance = f_importance / np.sum(f_importance)
f_importance_df = pd.DataFrame(f_importance)
df_importance = cols_df.join(f_importance_df,lsuffix='_features', rsuffix='_importance')
# 降順ソート
df_importance = df_importance.sort_values('0_importance', ascending=False)
df_importance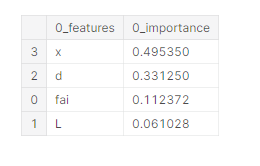
予測したい設計値を入力する
# 予測したい値を入れる
list_new = [[103,510,24,12],[101,505,22,11]]
test_new = pd.DataFrame(list_new)
test_new.columns = ["fai","L","d","x"]
test_new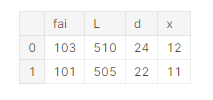
設計値に対する目的変数を算出する
pred_lgb_new = model_lgb.predict(test_new)
test_new["pred"] = pred_lgb_new
test_new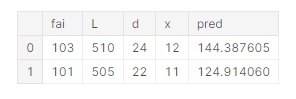
学習したモデルmodel_lgbを用いて、先ほど定義したtest_newデータフレームに含まれる設計値の場合の圧力差Pを予測します。
今回、2つの条件に付いて予測し、P=144.4, P=124.9という結果を得ました。
おわりに
このコードは下記にありますので、ぜひご自身のデータでも同じようにモデルが作れるか試してみてください。
https://www.kaggle.com/mnthasi/lightgbm-cae
機械学習の基礎的な部分を学べるように、最低限の知識を入れられる記事を用意しています。こちらもよろしければご覧ください。

以上、最後までお読み頂き、ありがとうございました。
コメント