Open-AIのAPIには、テキスト読み上げモデル(text-to-speech:TTS)があります。これを使うと、任意の文章を「とても自然に」読み上げた音声ファイルを作成できます。しかも英語/日本語など多言語に対応しているようです。
この記事では、Pythonのサンプルコードを示しながら、Open-AIを使ったテキスト読み上げの実行方法を解説します。
[ad]
Open-AI APIを使ったテキスト読み上げ
import os
from pathlib import Path
import openai
# API キーを直接指定
api_key = "sk-***" # 実際の API キーに置き換えてください
client = openai.Client(api_key=api_key)
# Use a relative path or a specific path as required
speech_file_path = Path("speech.mp3")
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
)
# Saving the audio response to a file
with open(speech_file_path, "wb") as f:
f.write(response.content)
上記コードを実行することで、inputで指定した「Today is a wonderful day to build something people love!」を読み上げたspeech.mp3ファイルを出力してくれます。以下がアウトプットです。
ちなみに、長い文章を読ませたいような場合(inputの文章が長く、別途テキストファイルで保存して読み込みたい場合)には以下のコードで実行できます。
import os
from pathlib import Path
import openai
# API キーを直接指定
api_key = "sk-**" # 実際の API キーに置き換えてください
client = openai.Client(api_key=api_key)
# Use a relative path or a specific path as required
speech_file_path = Path("speech.mp3")
# ファイル名を指定
file_name = "input_text.txt"
# ファイルを開いて内容を読み込む
with open(file_name, 'r', encoding='utf-8') as file:
input_text = file.read()
# OpenAI API に渡す
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input=input_text
)
# 音声ファイルとして保存
with open("speech_v2.mp3", "wb") as f:
f.write(response.content)実行フォルダに「input_text.txt」というテキストファイルを置いておくと、その内容を読み上げてくれます。成果物は以下の通りです。
詳細な利用方法はOpenAIのサイトに掲載されているので、こちらも参照ください。
voice=”alloy”と指定している声の主には、alloy(聞きやすい), echo(ちょっと低い声), fable(なまってる), onyx(ダンディ), nova(女性), shimmer(強そうな女性)の6種類が存在します。※()内は私の所感です。
日本語でもいける
OpenAIのテキスト読み上げは、言語に関わらず自然な音声を生成してくれます。試しに、別のブログ記事の冒頭部分を読み上げてもらいました。
EVが本格的に普及していくなかで、リチウムイオン電池の担う役割は重要です。この記事では、EV用のリチウムイオン電池の世界シェアをランキング形式で紹介します。
【最新】EV用リチウムイオン電池メーカーランキング
自然な日本語で読み上げてくれます。素晴らしい。
上記コードを実行すると、以下のようなエラーでうまく動きませんでした。
Traceback (most recent call last): File “C:\Users\Public\**\test2.py”, line 12, in <module> response = openai.Audio.speech.create( AttributeError: type object ‘Audio’ has no attribute ‘speech’
OpenAIライブラリのバージョンの確認してみたところ、使用しているOpenAIライブラリのバージョンが最新でないために、テキスト読み上げが機能しなかったようです。
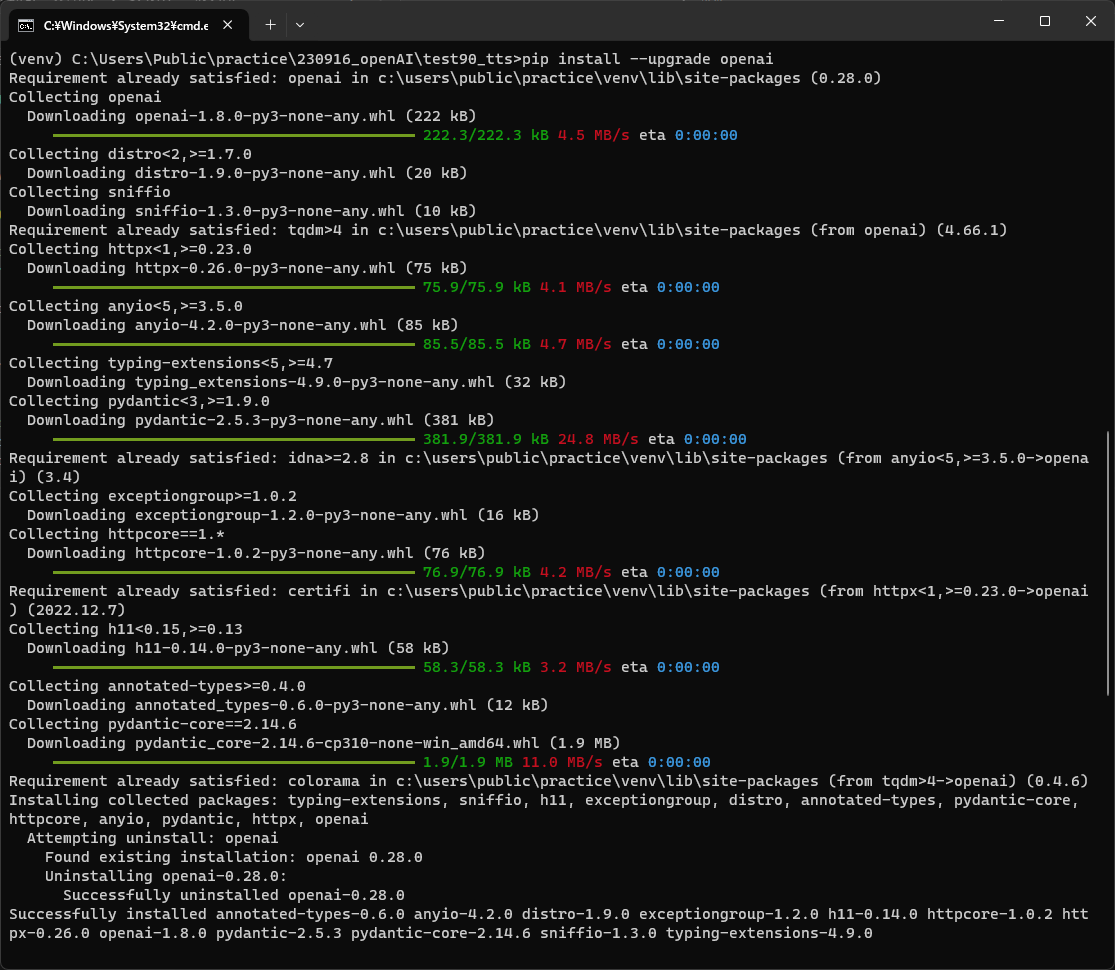
ライブラリを最新バージョンに更新するには、次のコマンドを実行します。
pip install --upgrade openai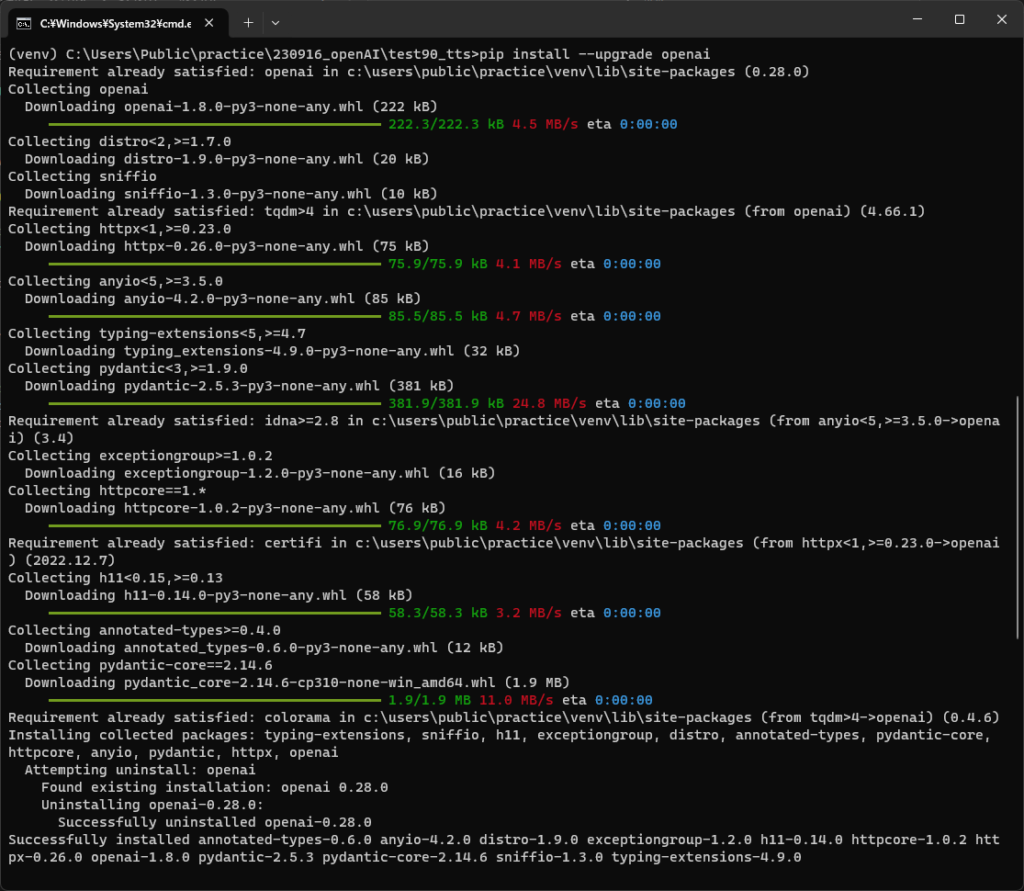
OpenAIのライブラリが最新版に更新され、テキストtoスピーチ機能が使えるようになりました。
文字数上限は4096文字
7000文字ほどの文章を読み上げようとすると、以下のエラーとなりました。
openai.BadRequestError: Error code: 400 – {‘error’: {‘message’: ‘1 validation error for Request\nbody -> input\n ensure this value has at most 4096 characters (type=value_error.any_str.max_length; limit_value=4096)’, ‘type’: ‘invalid_request_error’, ‘param’: None, ‘code’: None}}
どうやら、最大で4096文字までしか読み上げることができないようです。
英語の場合、1000文字の読み上げでおよそ1分程度の長さの音声ファイルになります。
APIキーの取得
APIキーは、OpenAIのページで設定できます。
ChatGPTアカウントから、API keysのタブを選択し、キーを発行できます。
API利用には課金が必要です。私は都度、10ドルずつ課金して、使い切ったらまた10ドル、といった使い方をしています。
読み上げのAPI料金はまだ安い方かも
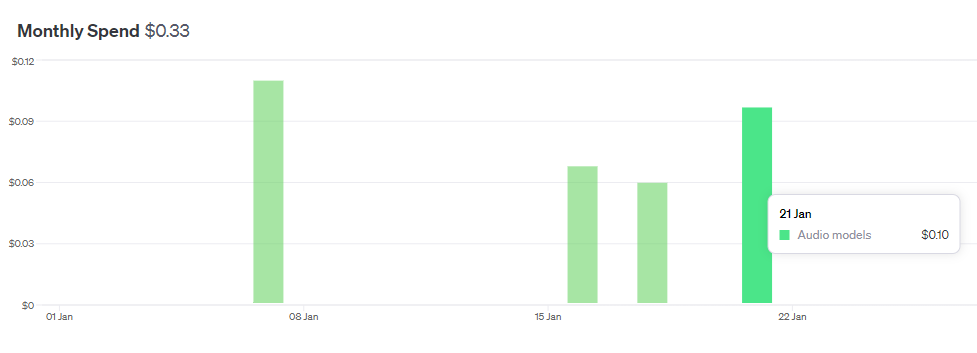
今回のようなテキストtoスピーチのモデルの料金は非常に安いです。
TTSの利用料金は0.1ドル以下(2000文字程度のテキスト読み上げを10回ほど)でした。入力している文字数が少ないため安く済んでいるのかもしれません。普段、筆者はGPT-3.5のAPIを利用していますが、日に0.05ドル程度使用(数万文字を処理)しており、費用はGPT-3.5と同じようなものかもしれません。
GPT-3.5が、GPT-4になるとAPI料金が跳ね上がります。以下の記事も参考になります。

OpenAIのAPIの使い方
APIというのは、プログラムを使って情報を取得したり、処理したりするための仕組みです。OpenAIのAPIは、AIのモデルにアクセスして、文章を生成したり、質問に答えたりすることができます。

APIの使い方を学ぶには、書籍「Python / JavaScriptによるOpen AIプログラミング」がおすすめです。この本では、プログラミングの基礎から始めて、実際のコードの例も提供してくれます。初めての人でもわかりやすく書かれているので、使い方を理解できます。
また、この本ではChatGPTだけでなく、OpenAIのサービス全般についても解説されています。たとえば、文字起こしのwhisper-1やDALL-Eといったツールについても説明されています。
OpenAIのドキュメンテーション(公式の解説書)やサンプルコードもありますが、私は日本語でわかりやすく解説してくれる本の方が好きです。
初歩的な内容ですが、WindowsのノートPCでPythonを実行する環境構築は以下の記事でも紹介しています。
何に使うの?
先日、英語での学会発表があり、自分のプレゼン原稿を読み上げて音声ファイルとして持ち歩いて聞きまくる、ということをしていました。AIはとても発音が良いので、自分自身の発音矯正にもなります。
利用時に気を付けたいこと
生成した音声の利用に関して、OpenAIのドキュメントには以下のような記述があります。
like with all outputs from our API, the person who created them owns the output. You are still required to inform end users that they are hearing audio generated by AI and not a real person talking to them.(私たちのAPIからのすべての出力と同様に、それらを作成した人が出力を所有します。その場合でも、エンドユーザーには、AIが生成した音声を聞いているのであって、生身の人間が話しているのではないことを知らせる必要があります。)
https://platform.openai.com/docs/guides/text-to-speech
生成AIを利用した音声であることは、エンドユーザ(聞き手)に伝える必要があるようです。
何かの参考になれば幸いです。
関連記事


コメント